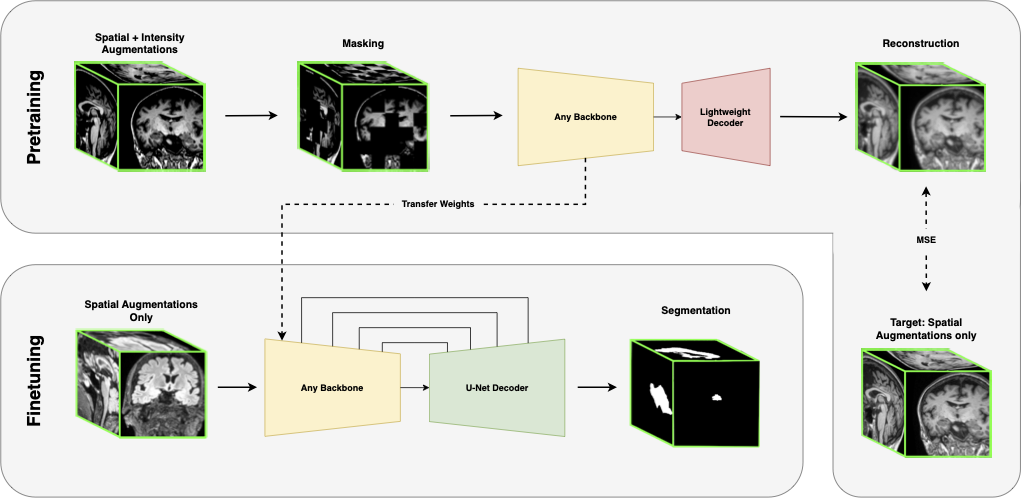
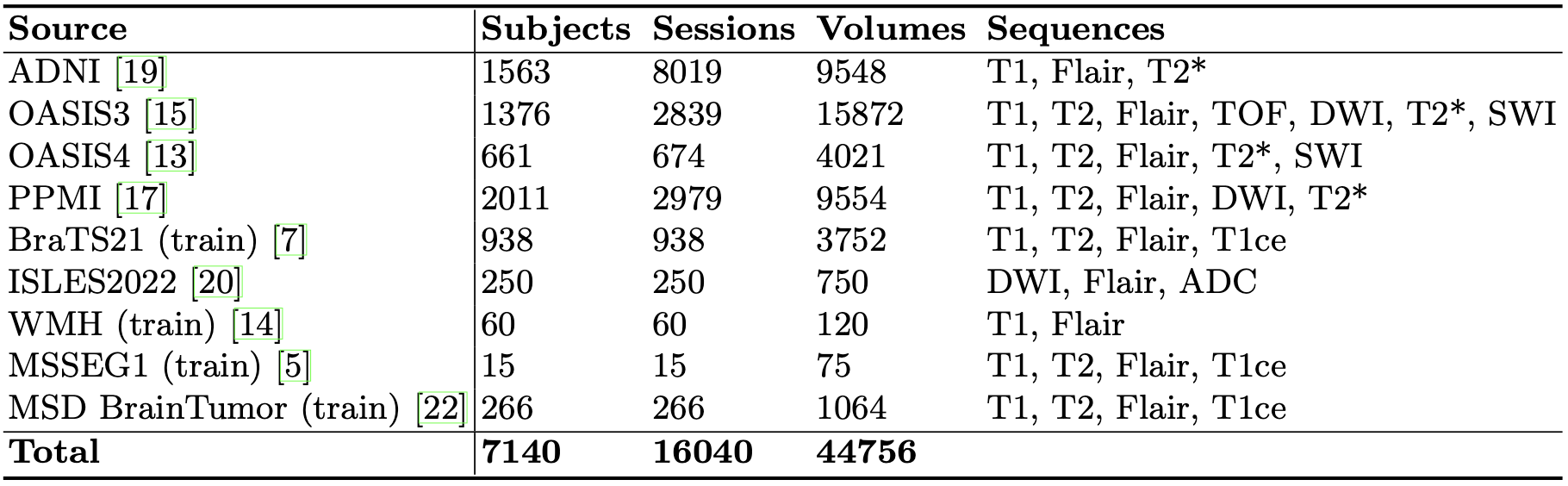
We evaluate AMAES in a setup designed to test the capacity of pretrained models by restricting
the amount of training data during finetuning to 20 labeled training
examples.
The evaluation is then performed along two dimensions: (i) How does AMAES compare to the
pretrained SwinUNETR?, and (ii) What is the impact of pretraining on downstream
performance?
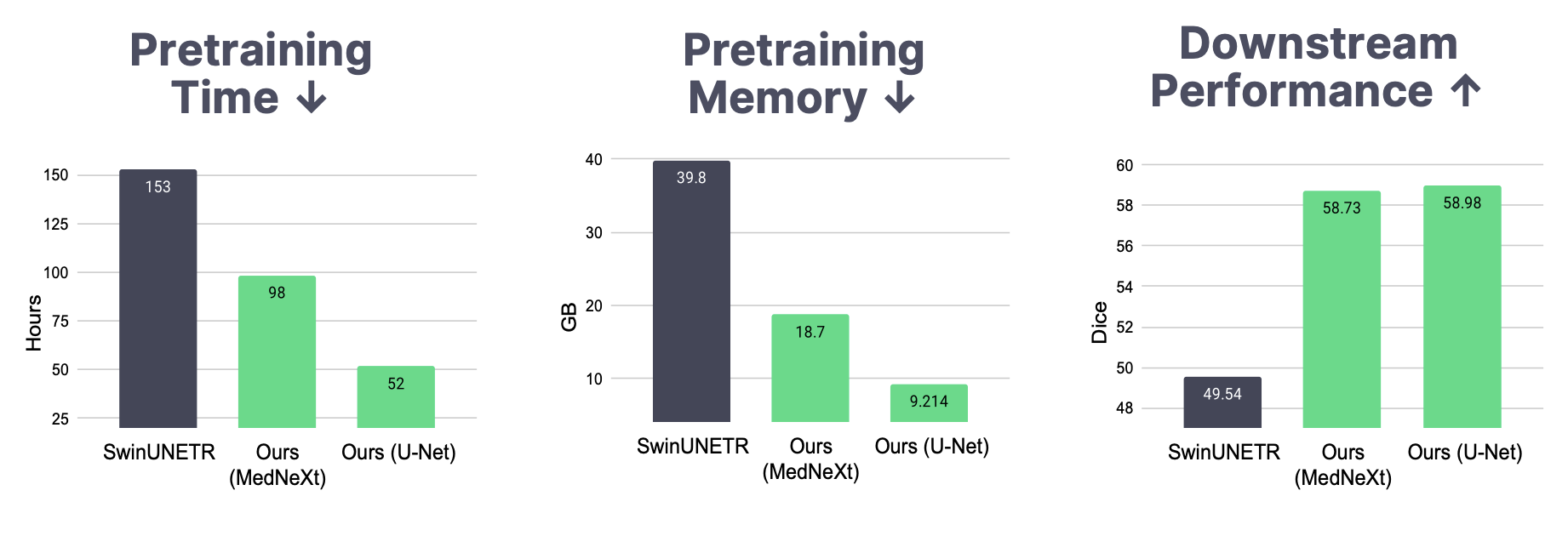
To evaluate (i), we pretrain SwinUNETR with the exact configuration given in on 🧠BRAINS-45K,
which includes both a contrastive loss, a rotation loss and a reconstruction loss, as well as a
different choice of masking ratio and mask size. To ensure a fair comparison, SwinUNETR is
pretrained for 100 epochs, similar to AMAES, and is pretrained with patch size 1283,
instead of patch size 963 and 90 epochs.
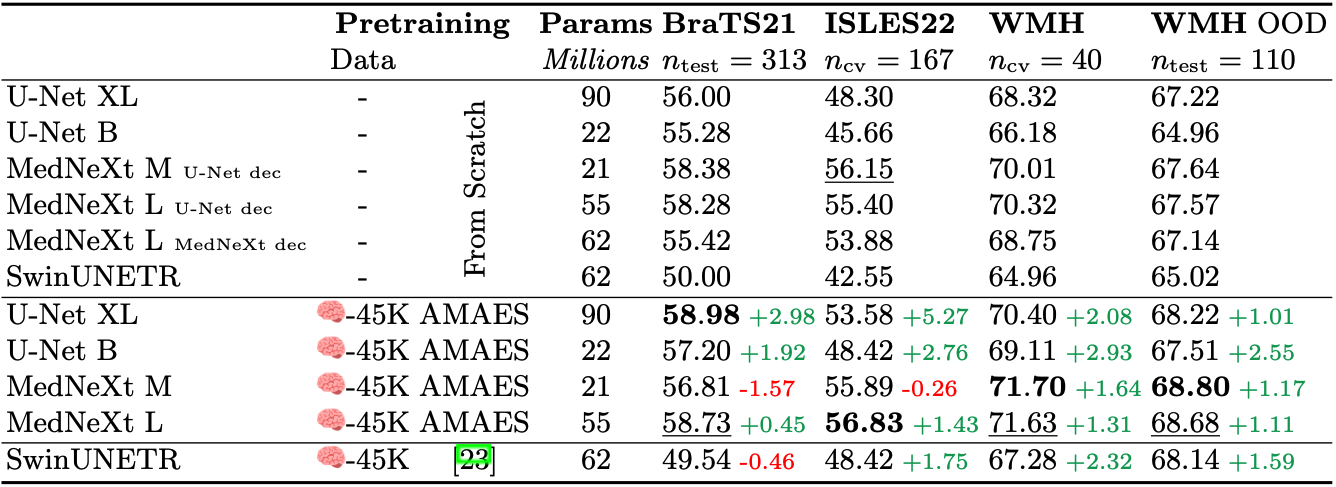
To address (ii), we apply AMAES to a set of convolutional backbones and evaluate the difference
between training from scratch and finetuning the pretrained model. The backbone models include a
U-Net in two sizes: XL (90M parameters) and B. The U-Net B is very similar in size to the one
used in nnUNet (22M parameters, when trained with the default setting max vram of 12 GB).
Further, we explore using the modernized U-Net architecture MedNeXt, which uses depth-wise
seperable convolution to introduce compound scaleable medical segmentation models. All MedNeXt
models are trained with kernel size 3 and do not use UpKern. The networks are finetuned and
trained from scratch using the same hyperparameters. Models trained from scratch use the full
augmentation pipeline. Results for both (i) and (ii) are given in Table 2.